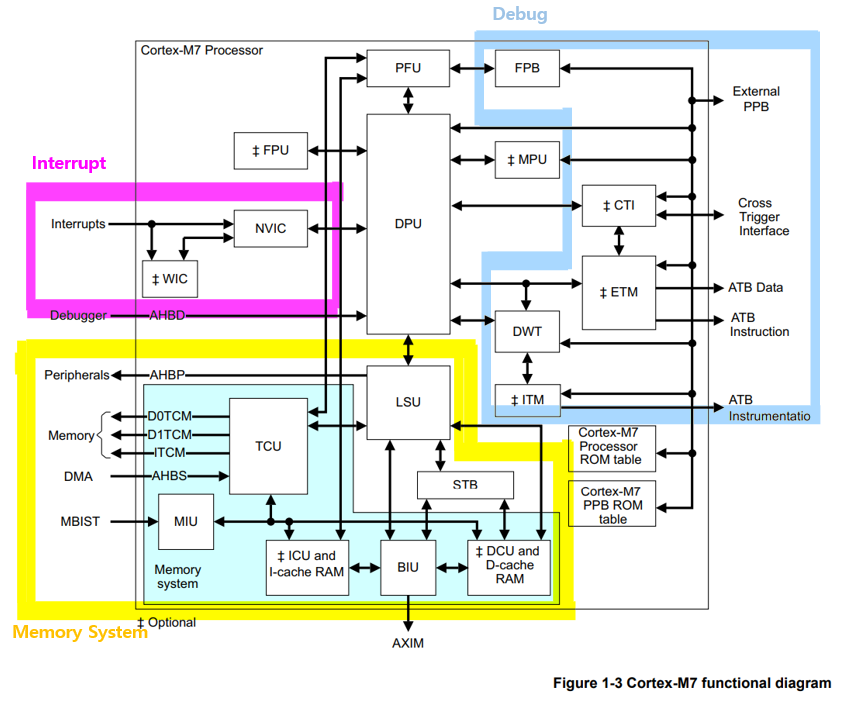
지난번에 이어 ARM Cortex-M7의 Component Block들에 대해 알아보도록 하겠다.
저번 포스트에서는 DPU밖에 다루지 못했지만.. 이번엔 빠르게 진행해보도록 하겠다 :)
(2) PFU(Prefetch Unit)
Prefetch라는 의미를 먼저 살펴보자.
기본적으로 CPU가 Fetch-Decode-Execute의 과정을 거친다는 것은 모두가 아는 사실이다.
이때, Prefetch라는 것은 Fetch 이전에 앞서서(Pre) Fetch를 하겠다는 의미임을 유추할 수 있다.
그렇다면 이러한 앞선 Fetch가 왜 필요할까?
그 이유는 물론 "Performance" 때문이다.
Prefetch를 통해서 Performance의 향상을 기대할 수 있다. 상황을 가정해보자.
CPU가 연산에 필요한 데이터를 요청하면 메인메모리, 캐시 등을 뒤져야할 것이다.(Fetch)
그러면 이때 CPU는 무얼할까?
데이터가 오지 않았으니 연산을 할 수도 없고 그냥 놀고있는 상태가 되어버린다. 즉, 매우 비효율적인 것이다.
Performance를 위해서는 CPU가 의미없게 쉬게 내버려둬서는 안된다.
따라서 CPU가 어떤 연산을 수행하는 동안 다음 연산에 필요한 데이터들을 예상해서 앞서서 Fetch해 놓겠다라는 개념이 바로 Prefetch 개념이다.
본론으로 돌아와서 Technical Referench Manual에 나온 특징에 대해 살펴보자.
1) 64-bit instruction fetch bandwidth.
2) 4x64-bit pre-fetch queue to decouple instruction pre-fetch from DPU pipeline operation.
1), 2) 특징을 통해 한번에 64-bit만큼 instrtuction을 fetch해 올 수 있고
이것 4개로 pre-fetch queue를 구성해서 prefetch를 구현하겠다~ 정도는 알 수 있겠다.
3) A Branch Target Address Cache (BTAC) for single-cycle turn-around of branch predictor state and target address.
4) A static branch predictor when no BTAC is specified
그런데 3), 4) 특징에 나타난 Branch Target Address Cache (BTAC)는 뭘까?
이는 Control Hazard와 관련이 있는데 Hazard는 다른 포스트에서 자세히 다루도록 하고 이번 포스트에서는 간단히 설명 후 넘어가도록 하겠다.
- BTAC(Branch Target Address Cache)
BTAC는 동작 수행 중 Branch 즉, 다른 주소로 Jump가 일어날 때 발생하는 문제를 해결하기 위함이다.
먼저 Branch에 대해서 먼저 알아보자.
int main() {
...
func1();
...
}
func1() {
...
}위 간단한 예시를 살펴보도록 하자.
프로그램이 main문을 수행하다 func1();을 만나 func1을 수행하기 위해 func1(){ }으로 들어가게 될 것임을 쉽게 알 수 있다.
이렇게 main을 수행하다가 subroutine으로 빠지는 것을 branch라고 한다.
이러한 branch는 처리가 상당히 까다로운데 그 이유를 위의 코드가 memory 주소에서 어떻게 위치하는지를 통해 살펴보도록 하겠다.
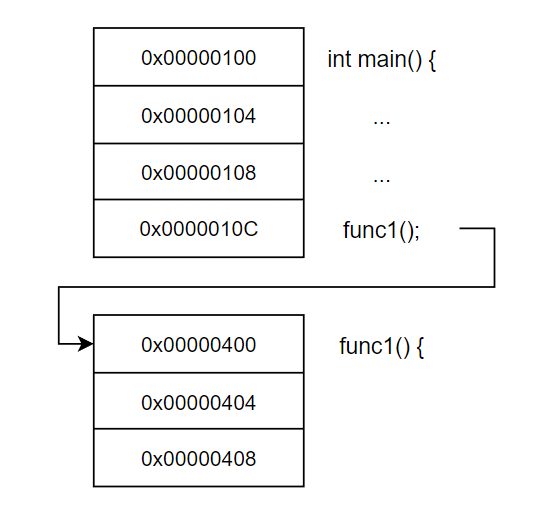
위에서 설명했듯이 프로그램은 0x00000100 번지에서 main 동작을 착실히 수행하고 있었을 것이다.
그러다 0x0000010C 번지에서 func1(); 구문을 만났고
func1 수행을 위해 0x00000400으로 가야한다.
당연한 것 같지만 바로 이 부분이 문제가 된다.
이렇게 Branch가 될 때, 주소를 Jump해야만 하는데 CPU가 Branch 여부를 판단하고 실제로 Jump가 이뤄지는 데에는 시간이 소요된다.
즉, 여러개의 Clock Cycle이 손해를 보게 되고 당연히 Performance는 떨어진다.
아마 Performance에 집착하는 입장에서 이는 두고볼 수 없었을 것이다.
그리하여 나오게 된 개념이 Branch 판단을 기다리지 않고 Branch를 미리 예측하고 움직이는 Branch Prediction이다.
다시 말해 Branch가 일어날지/일어나지 않을 지를 예측해 다음 주소를 Fetch함으로써 Cycle 손해를 보지않고 Performance를 향상시키겠다는 것이다.
ARM Cortex-M7의 PFU에도 이러한 Branch Prediction을 위해 BTAC(Branch Target Address Cache)가 존재하는 것이다.
추가적으로 Branch Prediction의 종류에는 Static Prediction과 Dynamic Prediction이 존재하는데 너무 길어질 것 같아(이미 길어졌지만 ㅎㅎ;) 이는 추후 Hazard를 다루면서 설명해보도록 하겠다!
(3) FPU(Floating Point Unit)
1) Instructions for single-precision (C programming language float type) data-processing operations.
2) Optional instructions for double-precision (C double type) data-processing operations.
FPU는 부동소수점 연산을 지원하는 Optional Unit인데
특징에 써진 것 처럼 쉽게 말하자면 C언어의 float, double 형식의 연산을 지원한다는 것이다.
물론 DPU 자체에서 이러한 소수점 연산을 구현하는 것은 가능하나 시간이 오래걸리고 복잡하다고 한다.
따라서 소수점 연산만 하는 FPU라는 전문가(?)를 둬서 Performance를 올려보려는 노력인 것이다.
결국 FPU의 존재 또한 Performance를 올리기 위함이였다 :)
오늘 포스트는 이만 마치고 다음 번에 이어서 살펴보도록 하겠다 :)








최근댓글