지난 Cortex-M7 intro에 이어 ARM Cortex-M7 Processor trm문서에 소개된 Component Block에 대해 알아보고자 한다.
아래는 문서에 소개된 Component Block 그림이다.

한번에 다 다루기에는 너무 많은 양이라 생각되어 나름대로 메모리 시스템, Interrupt, Debugging 3개의 영역으로 구분해보았다. 앞으로 여러차례의 포스트를 통해 관련 Component에 대해 차근차근 정리해나가보도록 하겠다.
(1) DPU(Data Processing Unit)
DPU는 Processor의 연산(Execute)를 당담하는 핵심적인 부분이다.
문서에 소개된 특징을 천천히 살펴보자.
1) Parallelized integer register file with six read ports and four write ports for large-scale dual-issue.
우선 첫번째로 소개된 register file이란 무엇일까?
- 레지스터 파일(Register File)
먼저, DPU가 Data를 처리하기 위한 Instruction이나 Data가 존재하는 곳은 모두 메모리이다.
하지만 빠른 처리속도를 자랑하는 DPU가 DRAM과 같은 느린 메모리에 직접 접근하여 데이터를 가져오는 것은 상당히 비효율적이다. 즉, DPU의 빠른 처리속도를 살리기 위해서는 그만큼 빠른 접근이 가능한 저장공간이 필요한 것이다.
이를 위해서 Core 내부에는 DPU가 접근하기에 메인메모리, 캐시메모리보다 더 빠른 하드웨어가 내장되어 있는데, 그것이 바로 레지스터 파일(Register file)이다.
이 레지스터 파일은 General Purpose Register와 SP,LR,PC 등으로 구성되어 있는데 이 부분은 추후 다뤄보도록 하겠다.
레지스터 파일의 개념은 알았으니
Large-scale Dual-issue를 위한 6개의 Read Port와 4개의 Write Port가 존재하는 Register File이란 무엇인지 알아보자.
여기서 Dual-Issue의 의미는 두개의 Instruction을 동시에 Fetch할 수 있다는 의미이다. 아래와 같이 말이다.

이렇게 동시에 여러개의 Instruction Fetch가 일어나는 것을 Super-Scalar 구조라고도 한다.
이것이 가능한 이유는 DPU내부에 ALU가 2개가 존재하기 때문이다.
쉽게 생각해서 병렬적으로 구성된 두 ALU가 각각 하나의 Instruction을 동시에 처리하기 때문이라고 생각하면 될 것 같다.
글로만 봐서는 잘 이해가 되지 않아 하나의 간단한 그림을 하나 만들어봤다.
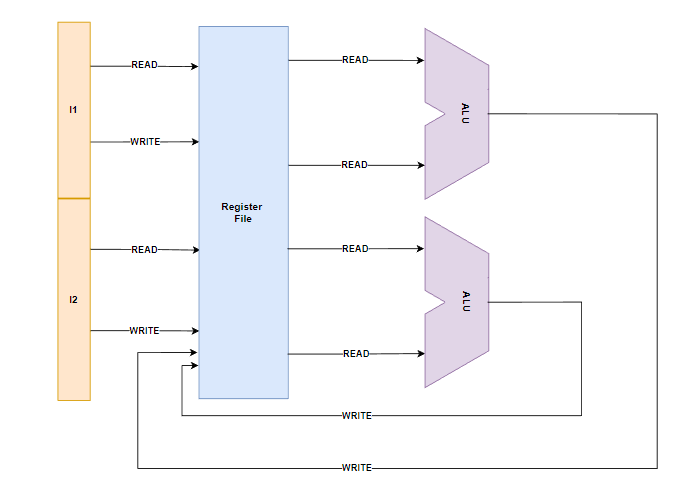
먼저, Instruction에는 Regsiter File에서 어떤 Register를 사용할 것인지에 대한 정보도 담겨있다.
따라서 위 그림에서 Instruction으로 부터 오는 Read/Write Port들은 Register File의 어떤 Register를 선택할 지 결정하는 Mux Control Signal이라고 생각해도 좋을 것 같다.
이외에 다른 Port들도 보게되면 ALU로 들어가는 Read Port 4개,
연산이 끝나고 그 결과값을 다시 Register에 저장하기 위한 Write Port 2개가 추가적으로 존재해총 6개의 Read Port, 4개의 Write Port가 존재함을 확인할 수 있다!
드디어 첫번째 특징에 대한 설명이 마무리 됐다.
아무래도 설명이 많이 길어진 느낌이다 ㅜㅜ 다음 특징부터는 좀 더 간단히 정리해보겠다.
2) Extensive forwarding logic to minimise interlocks.
두번째로 소개된 특징은 Extensive forwarding logic to minimise interlocks이다.
직역하면 interlock을 최소화하기 위한 forwarding logic이라는 것인데 forwarding logic에 대해 이해하고 넘어가면 해결이 되겠다.
- Forwarding Logic

위의 그림은 Forwarding Logic과 관련해 인터넷에 있던 하나의 예시를 참고하여 만들어본 자료이다.
SUB, AND, OR 총 3개의 operation이 차례로 Fetch된 모습을 볼 수 있는데 중요한 점은 첫번째 SUB의 결과인 $2가 이후 AND, OR연산에서 쓰인다는 점이다.
만약 Forwarding이 구조가 없다면 어떻게 될까?
SUB가 계산되기 이전의 $2값(쓰레기 값)으로 이후 AND, OR 연산을 해 엉뚱한 값을 얻을 것이다. 또 엉뚱한 값을 얻는건 연산을 안하느니만 못한 상황이니 이를 피하려면 처음 SUB가 완료되기 이전까지 AND, OR 연산을 멈춰(Stall)야 할 것이다.
이렇게 앞선 연산을 통해 얻은 결과가 이후 연산에 영향을 줄 때, 연산을 Stall해버리는 상황(문서 상 Interlock이라고 표현한 부분으로 보인다.)을 피하고자 나온 개념이 바로 "Forwarding Logic "개념이다.
그렇다면 어떻게 Forwarding을 한다는 것일까? 그림을 살펴보자.
그림에서 보게되면 첫번째 operation에서 ALU를 거치고 난 이후의 값을 forwarding하는 모습이 보인다.
이것이 가능한 이유는 연산은 ALU에서 수행되어 이미 끝난 상황이고 이후의 과정은 단순히 레지스터를 update하고 저장하는 과정이기 때문이다.
다음 연산이 굳이 앞선 연산의 결과 "저장"을 기다릴 필요는 없지 않은가?
따라서 계산이 끝난 값을 바로 Forwarding 해서 쓴다는 의미이다.
3) Two ALUs, with one ALU capable of executing SIMD operations.
DPU에 두개의 ALU가 있음은 위에서 이미 확인을 했다.
그런데 그 중 하나의 ALU가 SIMD operation을 수행할 능력이 있다고 한다.
SIMD는 또 무엇일까?
- SISD, SIMD
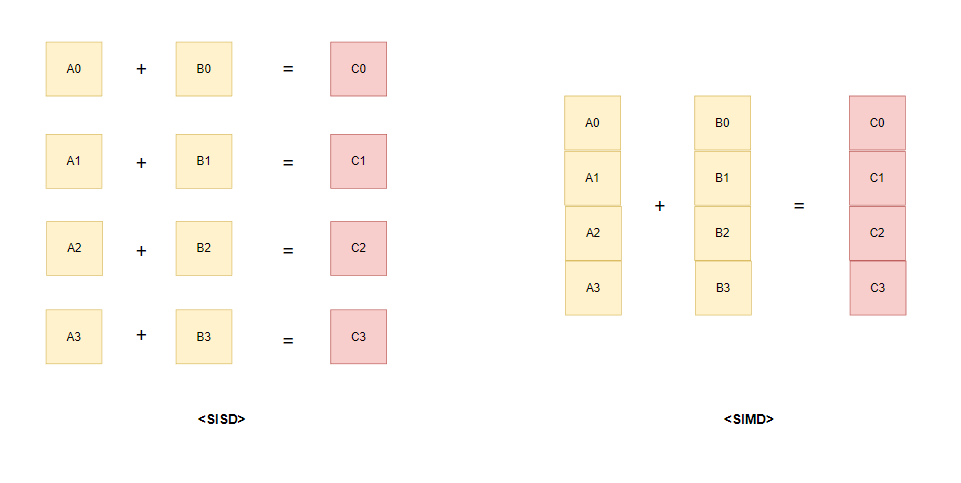
SISD(Single Instruction Single Data)는 하나의 Instruction(+)으로 하나의 Data를 처리하고
SIMD(Single Instruction Multiple Data)는 하나의 instruction(+)으로 여러개의 Data를 처리한다는 의미이다.
위 자료의 경우, SISD는 총 4번의 연산이 필요한 반면 SIMD는 한번의 연산으로 Data를 처리할 수 있다.
이러한 SIMD는 벡터/행렬 연산이 필요한 데이터 구조에 적합하다고 한다.
SIMD 개념에 대해 대략적으로 알았지만 정확히 SIMD가 어떻게 동작하는지는 파악하지는 못했다..
다만 Cortex-M7의 Instruction Set에 SIMD를 구현하는 Instruction이 존재하는 것으로 보아 SIMD를 지원할 수 있는 ALU가 존재한다! 정도로 이해하고 넘어가도록 하겠다.
모르는 개념이 많아 횡설수설하다보니 생각보다 시간이 많이 길어졌다. :(
모두 좋은 하루 되시길 바라며 다른 Component들은 이후 포스트에서 이어서 살펴보도록 하겠다.








최근댓글