안녕하세요. 새로운 Section이네요.
HW설계 관련해 최근 Bus, CPU 등등을 공부하면서 컴퓨터 구조 지식이 정말 많이 필요하고 도움이 되겠더라구요.
그래서 [컴퓨터구조] 라는 Section을 따로 만들어 봤습니다.
앞으로 공부하다 컴퓨터 구조 관련해서 기록할만한 내용이 있으면 포스팅 해보도록 하겠씁니다.
암튼 이번 포스트에서는 ARM Cortex를 다루면서 나오기도 했었던 Hazard에 대해서 정리해보려고 합니다.
Hazard는 사전적으로 "위험"을 의미하는데 Hazard에 대해 공부하고 나서 보니 Performance에 위험하다..로 제 맘대로 재정의 해버렸어요. ㅋ_ㅋ
그러면 시작해보도록 합시다.
Hazard에는 대표적으로 3가지가 있습니다.
1) Structural Hazard, 2) Data Hazard, 3) Control Hazard 가 있고 각각이 무엇이고 이러한 Hazard를 어떻게 해결하는지 확인해봅시다.
1) Structural Hazard
Structural Hazard, 직역하면 구조적 Hazard죠.
즉, Software적인 부분이 아니라 Hardware적으로, 구조적으로 문제가 있다는 이야기입니다.
다음 예시를 봅시다.
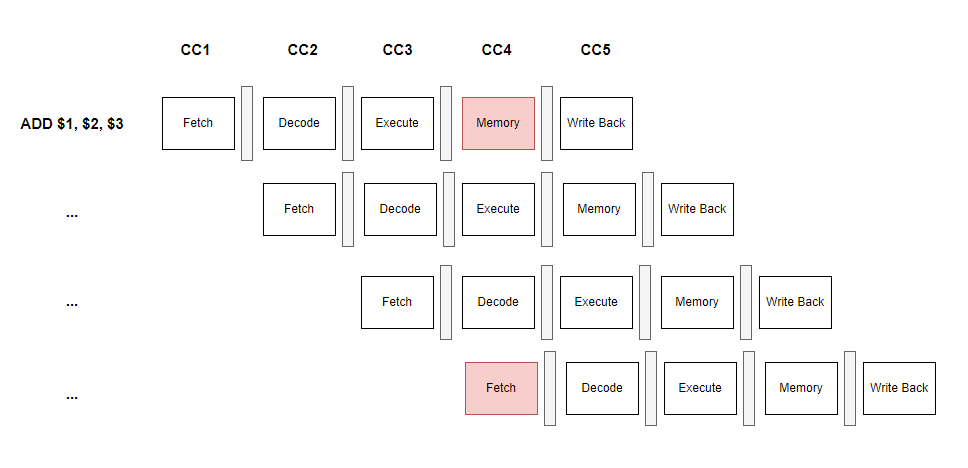
위의 예시에서 Clock Cycle 4(CC4) 때를 유심히 봅시다.
파이프라인 과정 중 Fetch과정에서 instruction을 fetch하려면 당연히 instruction이 담겨있는 메모리에 접근해야합니다.
또한 파이프라인 과정 중 Memory과정에서 결과값을 메모리에 기록하려면 메모리에 접근을 해야겠죠.
이런 상황에서 Instruction과 Data가 하나의 같은 메모리에 들어있다면 어떨까요?
메모리라는 자원은 한정적으로 존재하는데 동시에 여러 Stage에서 접근하고 있기 때문에 둘중에 하나는 양보를 해야합니다. 이렇게요.
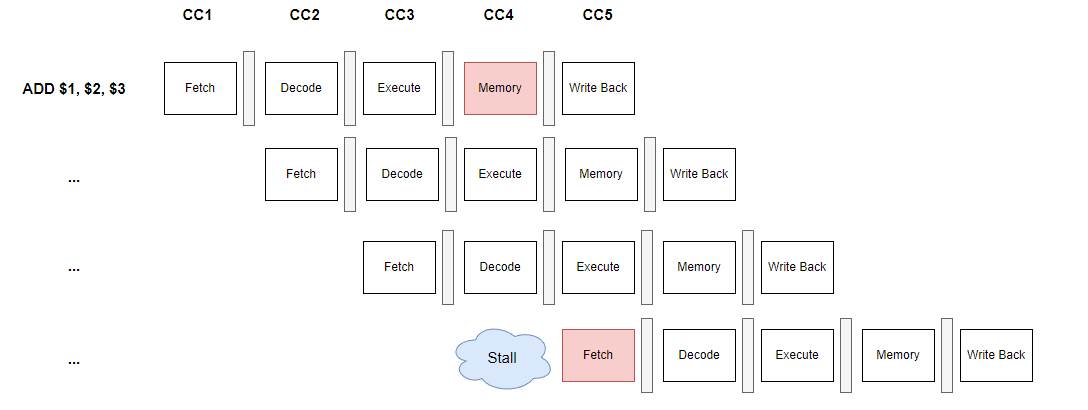
Fetch가 양보를 하면서 한 사이클을 Stall(중지) 시킨 것이 보이시죠?
이렇게 Stall함으로써 한 사이클을 손해보긴 했지만 하나의 메모리에 여러 Stage가 동시에 접근하는 상황은 피할 수 있겠네요.
암튼 Structural Hazard는 위와 같이 하나의 Functional Unit을 두고 서로 다른 stage에서 사용하려고 하는 경우에 발생을 합니다. 그렇담 해결책에 대해서 알아봐야겠죠?
1-1) Structural Hazard 해결책
사실 Stall을 시키는 것도 해결책이라고 할 수 있습니다.
하지만 Stall을 한다는 것 자체가 특정 사이클동안 노는거기 때문에 Performance측면에서 좋은 상황은 아닐겁니다.
해결책은 간단합니다.
메모리 하나에 Data, Instruction을 담는 것이 아니라 Data Memory와 Instruction Memory로 분리하는 것입니다.
이렇게 하면 메모리에 Data를 저장하는 중에 다른 Stage가 메모리에서 Instruction을 Fetch하더라도
서로 다른 메모리에 접근하는 것이기 때문에 이런 Structural Hazard는 발생하지 않겠죠!
2) Data Hazard
두번째로 소개할 Hazard는 Data Hazard입니다.
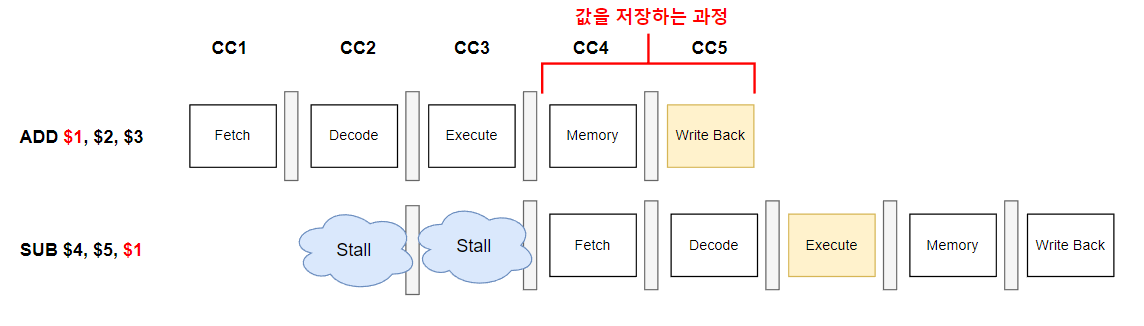
Data Hazard는 뒤의 instruction이 앞의 instruction의 결과를 사용할 때 발생하는 Hazard입니다. 다음을 살펴봅시다.
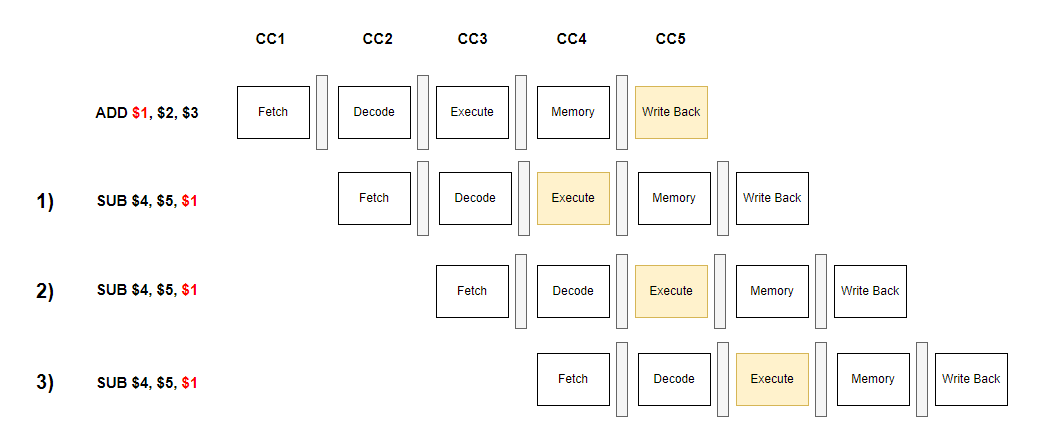
보게되면 ADD라는 Instruction을 통해서 $1 = $2 + $3이 되고 있고 이 ADD연산의 결과 $1을 이후의 instruction에서 사용하려는 모습이 보이네요.
여기서 퀴즈! $1 값을 사용하는 SUB instruction이 1,2,3번 중 어디에 와야 문제가 생기지 않을까요?
정답은~~ 3번 입니다. 이유를 살펴봅시다.
SUB에서 ADD의 결과 $1을 이용하려면 ADD의 결과가 $1에 업데이트가 된 이후에 가져다 써야합니다.
ADD의 결과가 레지스터 $1에 업데이트가 되는 시점은 바로 Write Back 시점이죠.
즉, $2에 결과가 업데이트 되기 이전(Write Back시점 이전)에 다른 instruction에서 $2를 가지고 Execute를 해버리면 ADD연산이 안된 잘못된 값, 쓰레기 값으로 연산을 하는게 되는 겁니다.
따라서 ADD에서 $2에 결과를 저장하는 Write Back이 되고 난 이후 Execute를 수행하는 3번이 정답입니다.
다시 표현하면 다음과 같겠네요.
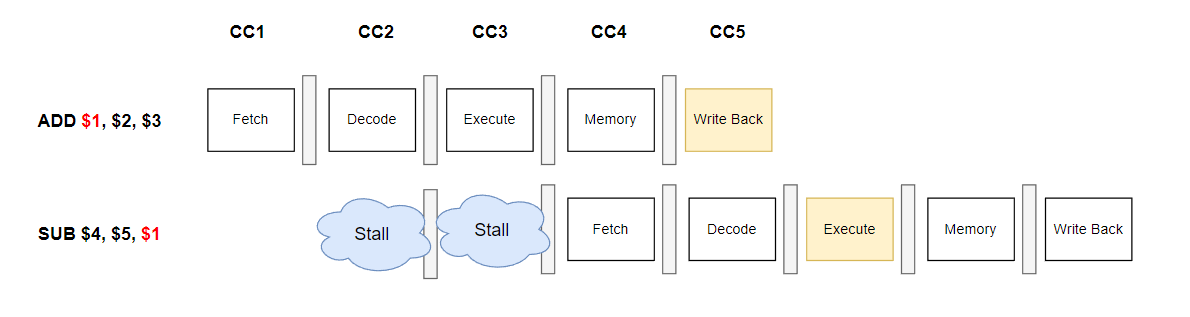
보시다시피 2사이클이 Stall이 되면서 손해를 보는 꼴이 됩니다.
그렇다면 이런 Data Hazard. 해결하는 방법도 알아봐야겠죠?
2-1) Data Hazard 해결책
해결책은 ARM Cortex의 특징에서도 본적이 있던 'Forwarding Logic'을 이용하는 거에요.
위에서 봤던 파이프라인을 다시 볼께요.
보시게 되면 사실 우리가 하고자 하는 연산, 여기서는 ADD가 되겠죠.
ADD 연산은 Execute Stage에서 모두 끝나고 이후에 Memory나 Write Back은 모두 결과값을 저장하는 과정이에요.
Forwarding Logic은 바로 이 부분을 공략했습니다.
ADD의 결과값을 이용하는 SUB가 ADD의 결과값 저장을 굳이 기다려야만 할까요?
기다리지 말고 실질적인 연산이 끝나는 Execute Stage에서의 결과를 Forwarding 시켜버리자! 라는게 Forwarding Logic의 개념입니다. 아래와 같은 식이죠.
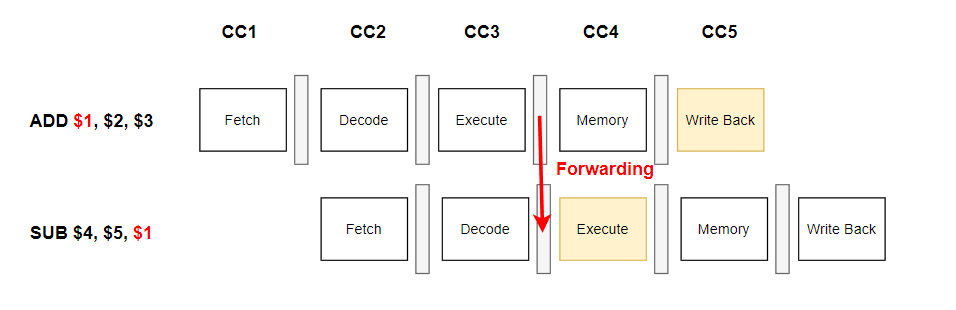
이렇게 앞선 instruction의 결과값 저장을 기다리지 않고 Forwarding해서 후속 instruction을 진행해버리니 Stall 과정이 사라지고 Performance를 챙길 수가 있는 겁니다.
3) Control(Branch) Hazard
마지막으로 Control(Branch) Hazard입니다.
괄호 안에 Branch라고 적힌 것 처럼 Control Hazard는 Branch와 관련된 Hazard입니다. 다음을 살펴봅시다.
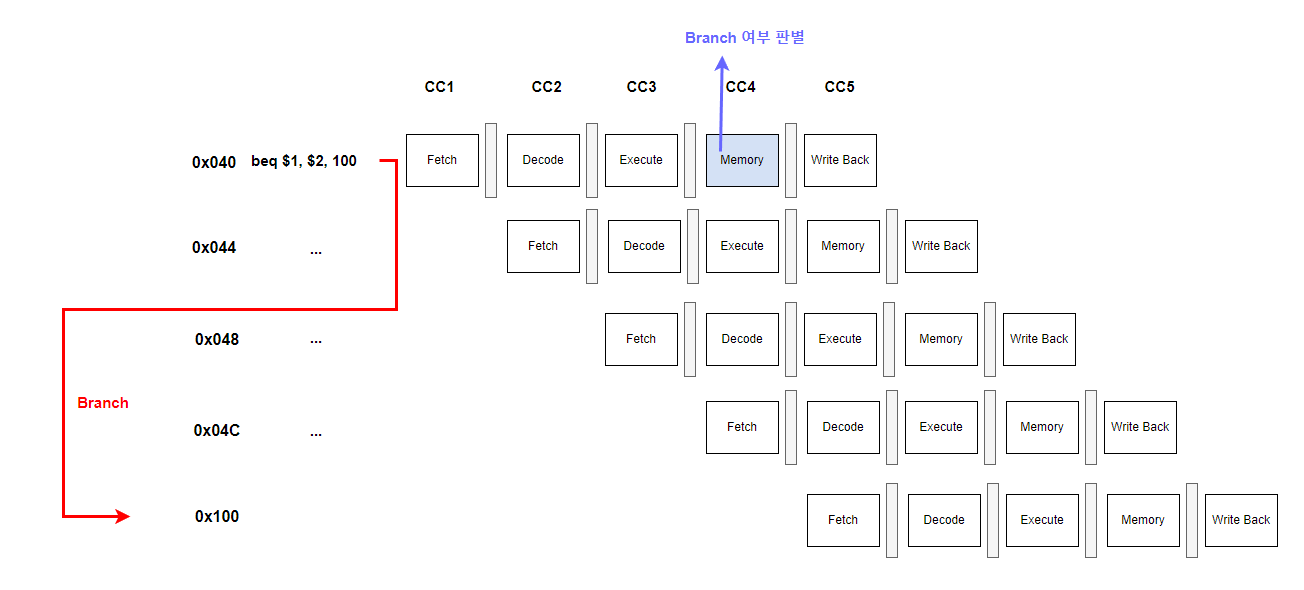
참고로 여기있는 어셈블리 코드들은 그냥 막 적은 것이니 이해 부탁드릴게요..!
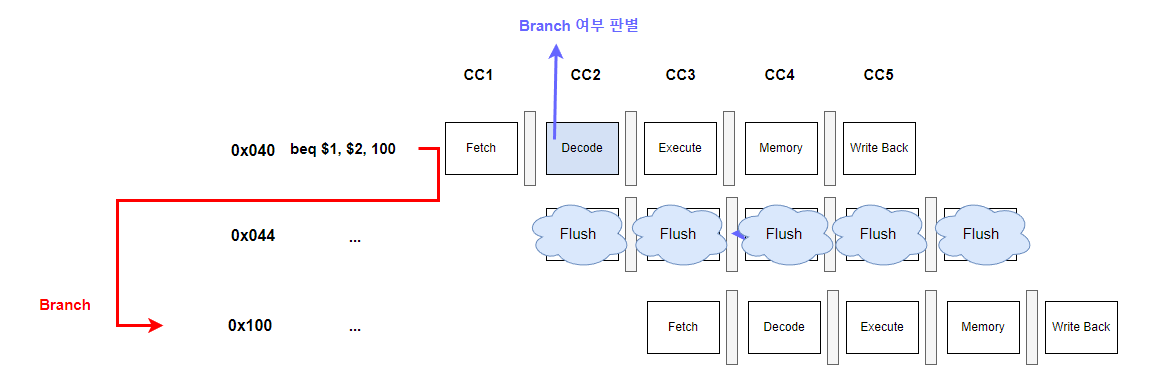
아무튼 0x040 번지에 $1과 $2를 비교해 같으면 0x100번지로 Brach(jump)하는 코드가 있다고 합시다.
여기서 중요한 점은 Branch여부를 판별하는 시점 즉, beq에서 $1과 $2가 equal한지 검사하고 pc값을 setting하는 과정은 Memory Stage에서 완료됩니다.
다시 위의 상황으로 돌아와서 정리해보자면
0x040번지에서 branch 구문 beq가 던져졌고 branch여부가 판별되는 memory stage (CC4)이전에는 branch를 할지 안할지 CPU는 알 수가 없죠.
그래서 CPU는 평소 관행대로 address를 4씩 늘려가며 (0x044, 0x048, 0x04C ... ) 작업을 합니다.
이때, 대망의 memory stage(CC4)에서 $1과 $2가 같아 Branch를 해야한다고 판단을 내렸다고 한다면 어떻게 될까요?
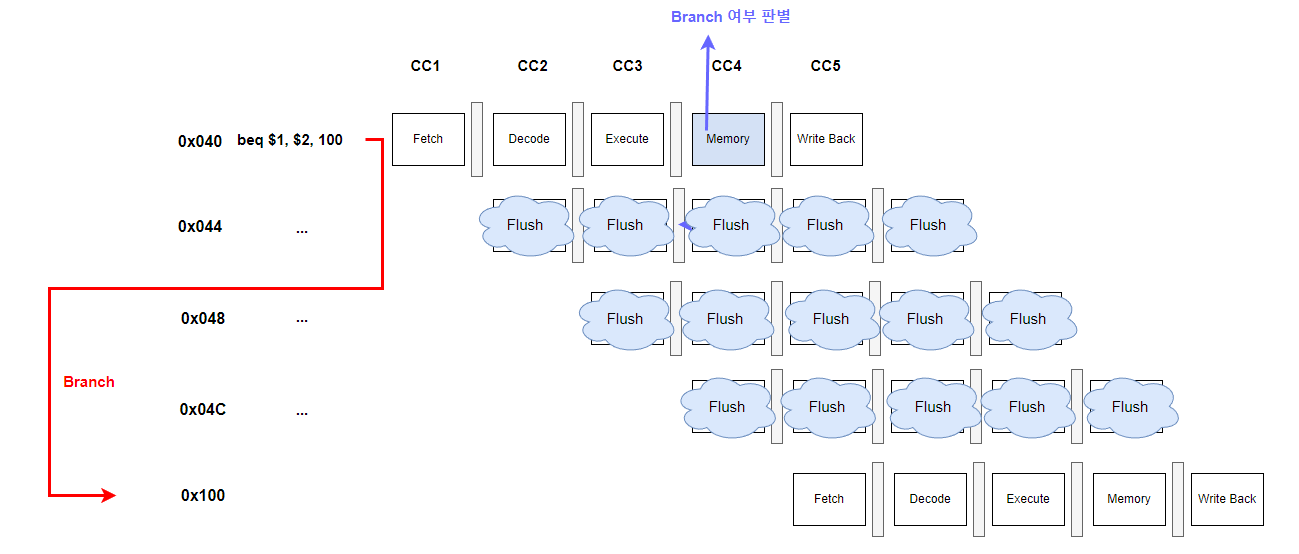
CPU가 branch를 할지 안할지 몰라 그냥 평소대로 진행하던 것은 모두 헛수고였습니다.
0x100번지에 있는 instruction을 fetch해야하는데 필요없는 0x044, 0x048.. 번지의 instruction을 fetch하고 있었다는 의미죠.
따라서 실제 branch가 이루어진다면 다음과 같이 잘못 fetch된 것들을 모두 폐기처분, flush를 시킵니다.
이렇게 branch로 인해 발생하는 hazard가 바로 control hazard이고 위에서 볼 수 있다시피 3-cycle 손해를 보게 됩니다.
정말 critical하지만 이런 control hazard도 해결하는 방법이 존재합니다. 살펴보시죠.
3-1) Control Hazard 해결책
Control Hazard의 가장 큰 문제는 branch 여부를 판별하는 시점이 너무 늦다는 겁니다.
따라서 branch 판별 시점을 앞당긴다면 어느정도 해결이 될 수 있겠죠?
그래서 첫번째 해결책은 Branch 판별 시점을 앞당기는 겁니다.
기존 Memory단계에서 Branch 판별 여부가 결정이 되었는데 이 시점을 Decode까지 땡길 수가 있습니다.
Decode Stage에 Adder와 Comparator를 추가하여 말이죠.
이렇게 판별 시점을 땡기면 다음과 같이 Cycle 손해를 줄일 수가 있겠네요.
비록 1-Cycle Flush가 일어나긴 하지만, 기존 3-Cycle Flush에 비해서 장족의 발전입니다.
그래도.. 1-Cycle의 손해도 안보는게 Performance적으로 좋겠죠.
그래서 0-Cycle 손해를 실현시키고자 나온 두번째 해결책이 Branch Prediction입니다.
- Branch Prediction
Branch Prediction은 말그대로 Branch를 예측하겠다는 말이에요.
Branch를 예측해? 어떻게?
예측 방법과 관련해 Branch Prediction 종류로는 두가지를 들 수가 있는데요.
Static Prediction과 Dynamic Prediction이에요.
- Static Branch Prediction
Static Branch Prediction은 beq와 같은 Branch 구문이 나오면 묻지도 따지지도 말고 branch해라! 혹은 branch 절대 하지마라! 라고 사전에 정의를 해 두는 겁니다.
예를 들어 branch 구문이 나올때, 아.묻.따 branch해라 라고 설정이 되어있다면
branch instruction이 나왔을 때, branch 판별 여부를 기다리지 않고 일단 해당 주소로 branch를 해버립니다.
그렇게 해서 실제로 branch가 일어나야 했으면 예측 성공이 되면서 0-cycle손해를 보는거고
만약 branch를 하지 말아야 했던 상황, 즉 예측 실패를 했다면 그때 flush하고 1-cycle 손해를 보는거죠.
- Dynamic Branch Prediction
Dynamic Branch Prediction은 Static과 달리 Run time(프로그램 실행 중)에 Branch Prediction을 합니다.
쉽게 말하면 Branch History를 이용한다고 할 수 있는데요.
Branch instruction이 나왔던 주소 값(PC), 그리고 실제 jump를 수행했는지 여부까지 branch prediction buffer(branch history table)에 저장을 합니다.
그리고 과거에 경험했던 branch구문이 온다면 과거에 jump했는지 안했는지에 따라서 jump를 할지 말지 예측을 하는거죠.
아무래도 실제 history에 기인하다보니 static보다는 적중률이 높겠네요. ㅎ
Hazard 관련해 공부한 내용은 여기까지입니다!
컴퓨터 구조는 많이 해본적이 없어 걱정했는데 다행히 아직까진 흥미로운 것 같네요 ㅋ_ㅋ
다음에 또 공부한 내용 들고 찾아오겠습니다.
좋은하루 되세요!







최근댓글